



A History
The pioneers of early computation had a beautiful dream. Technology as they envisioned it would be a democratizing force. It would empower everyday people to build and control tools that improved their lives. These “bicycles for the mind” would give wings to their creativity and materialize solutions to even the most niche and idiosyncratic needs. To make this dream a reality, the pioneers would need to marry permissionless composability with user-friendly interfaces.
Permissionless composability would enable new innovations through the combination of technologies and modules without a central authority telling people what they can or can’t do with these technologies. User-friendly interfaces would make this power available to the masses, not just the “priesthood of programmers”.
The purpose of computers is human freedom.
—Ted Nelson, 1974
For a time, the pioneers made progress towards this dream. In the 1970’s, researchers at Xerox PARC developed the earliest forms of copy and paste in text editors, which Apple then expanded into a universal API at the operating system level.

Copy and paste is a bit like public libraries—if we hadn’t inherited these blessings from our forefathers, their proposal would seem wildly radical to today’s sensibilities (You want to allow unfettered data transfer between programs created by different companies? What’s next, taxpayer-funded books?). Copy and paste enabled user-friendly interoperability of data between programs, which in turn enabled a vast degree of composability for people who otherwise couldn’t speak the language of computers. Other revolutionary attempts of this era to combine composability with usability included Hypercard (1987), digital spreadsheets (1979), and Logo (a programming language designed for children, created in 1967).
Amidst the innovation, however, a civil war was brewing.
As technology became more valuable to a broader market, it also attracted the attention of large corporations and investors who saw an opportunity for profit in digital’s zero-marginal cost production. In order to make a profit, however, they needed legal intervention. Software wasn’t subject to copyright and therefore all software and its source code existed in the public domain without licenses. In 1983, US courts (ruling in favor of Apple) granted software the legal status of literary works, enabling companies to claim ownership and profit from their creations. That same year, IBM announced that it would no longer distribute source code along with its software—making modifications by the end-user impossible.
But software-for-profit had detractors. A month after the 1983 ruling, Richard Stallman founded the GNU Project with the goal of giving users control by collaboratively developing and publishing free, open-source software. The open-source movement of volunteer developers positioned themselves as the Rebels against corporate tech’s Galactic Empire.
Clashes erupted. Microsoft’s Steve Ballmer called open-source “a cancer” while leaked internal documents revealed a strategy to push proprietary protocols that would limit interoperability and kneecap open-source alternatives to Microsoft products. As major tech companies began to rely on open-source software, some open-source resorted to sabotage by deleting their own code.

However fierce the battle, neither side of this fraternal conflict could realize the original dream of user-friendly and permissionless composability.
For-profit tech companies sought the ROI of usability (it’s no coincidence that ‘user-centered design’ also emerged in the 1980’s) and marshaled their vast resources towards this aim even as the underlying technology became steadily more complex. Today the software produced by Big Tech is easy to use, but only in the predetermined ways that their creators allow. That means closed ecosystems, limited interoperability, no composability, and strict permissions.
Conversely, the open-source community prioritized permissionless composability, but this came at the expense of usability. Open-source software is built by volunteers without profit—and developing user-friendly interfaces is expensive, especially as technology becomes more complex. Therefore most open-source software is built by developers for other developers.
Corporate software built easy-to-use tools, but at a cost and without composability. Open-source software supported permissionless composability, but their tools weren’t user-friendly.
An Opportunity
This was the state of computation until last week, when OpenAI released ChatGPT.
For months we’ve marveled at the fantastic hallucinations of image generators like Midjourney, Dall-E, and Stable Diffusion. We’ve been awed by GPT-3’s ability to write essays and short stories.
ChatGPT is an implementation of GPT-3 that is specifically designed for conversational language tasks. ChatGPT takes the capabilities of large language models (LLMs) further by introducing the ability to converse with the LLM and reference past subjects of conversation.
Large language models like ChatGPT are trained using deep learning, a powerful form of machine learning that involves training a network of interconnected neurons to recognize patterns in data. In the case of language models, this means feeding the neurons vast amounts of text data so they can learn the patterns of language. Once trained, the model can use this knowledge to generate human-like text when given a prompt.
The more text data the model is trained on, and the more powerful the computer hardware used to train it, the better it becomes at generating realistic text. That's why ChatGPT can produce such convincing and coherent responses.
Don’t believe it? Those last two paragraphs were generated by ChatGPT.







Twitter has been abuzz since the release as people share their amazement and skepticism of what ChatGPT can do (the second coming of Tolstoy it is not—its writing tends towards the banal and sophomoric, often confidently expressing information that may not be correct). While rewriting the lyrics of Apple Bottom Jeans in the style of Soviet propaganda is a great party trick and take-home essays may soon be extinct, ChatGPT has another trick up its sleeve that is far more consequential.
ChatGPT knows how to code.





On my first morning with ChatGPT, I asked it to create a custom client intake questionnaire with multiple question types and complex branching logic, where only one question is displayed per page. I've been looking for a program like this for a while, but none of the available web form services met my particular needs. I'm also a terrible programmer. Not only did ChatGPT generate plausible questions for my use case, it produced a working python script that met my criteria in seconds.

Of course, there’s some technical knowledge expressed just in knowing enough to request a python script. What if I don’t know what I need? A single python script isn’t enough. Again, ChatGPT is a generous and understanding developer.

But I don’t just want it to work, my clients will see this! I need it to look good too. ChatGPT, help!

One more thing — I forgot to tell it that I wanted my questions to show up one at a time. Can we rewrite the code to do that? Of course, it’ll just whip up some javascript for us.
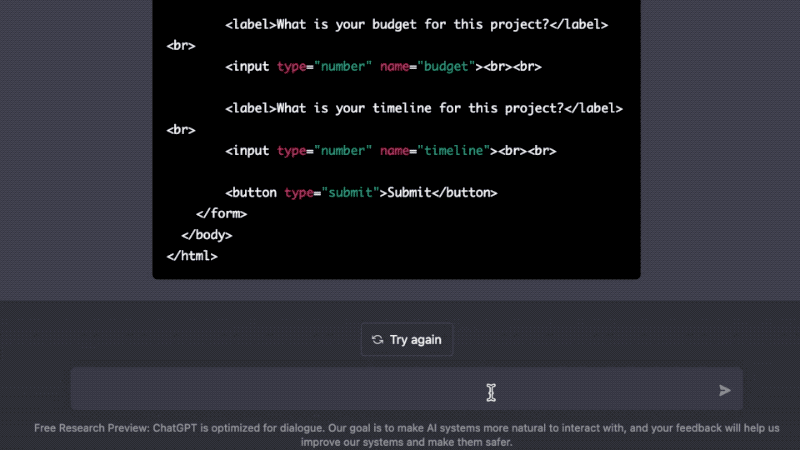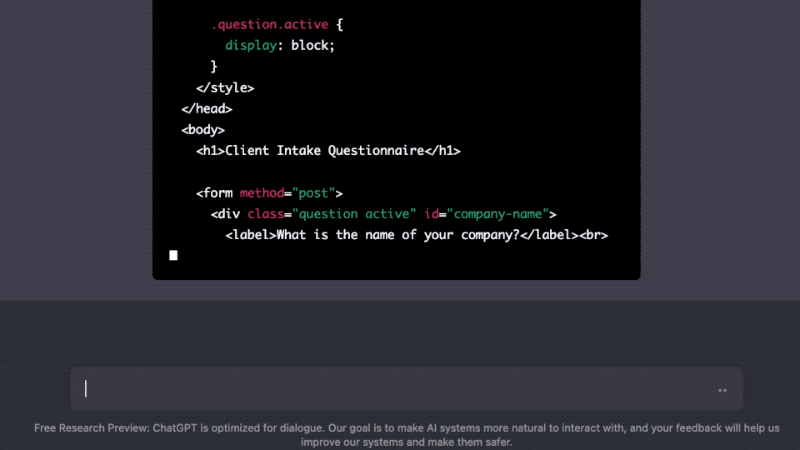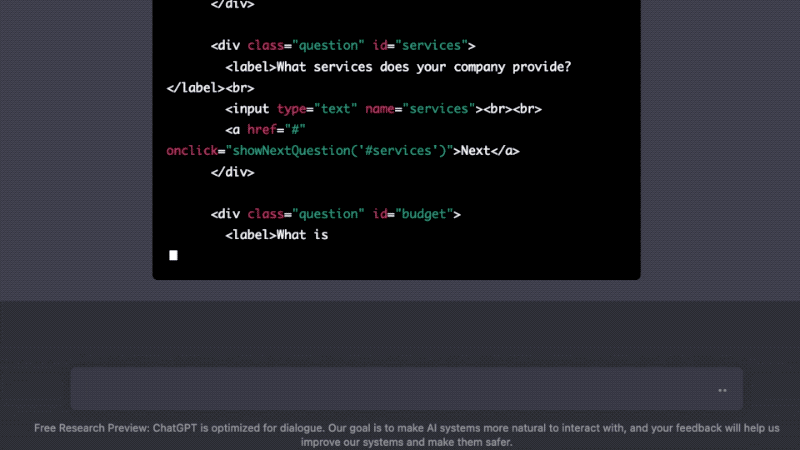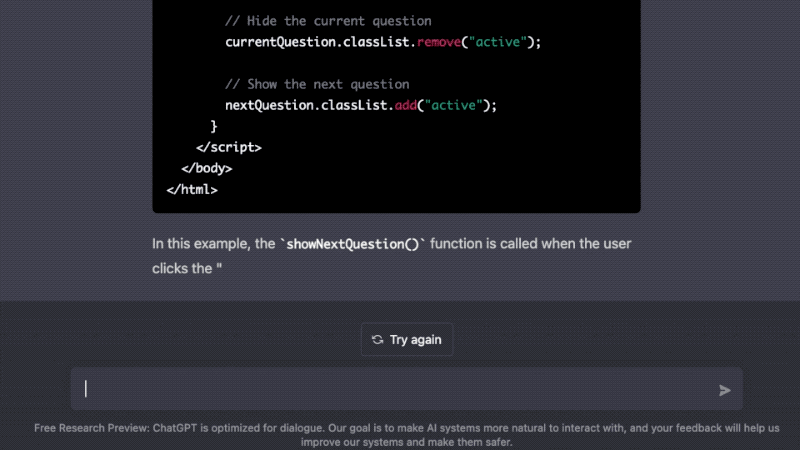
The code is often incomplete and not entirely free from error, but ChatGPT will also assist and explain any errors encountered along the way (poetry may not be dead but Stack Overflow probably is). As someone who is literate enough to ask questions in plain English but not technically proficient enough to memorize syntax or write error-free code, I find ChatGPT's abilities to be incredibly empowering. What would have taken me days or weeks to do on my own now takes just seconds or minutes with ChatGPT's help.
Whatever our current AI’s shortcomings as a developer may be, it’s clear they will be short-lived. Yesterday, Google’s Deepmind announced AlphaCode, which writes code of a high enough quality to place in the top half of coding contests.

The implications of AI-written software—prompted in plain English—are enormous. In a recent post I discussed the concept of ‘design for emergence’ and identified three criteria for this design paradigm (which aligns closely with that envisioned by computation’s early pioneers). They were:
1. The designer can be meaningfully surprised by what the end-user creates with their tool.
2. The end-user can integrate their local or contextual knowledge into their application of the tool.
3. The end-user doesn’t need technical knowledge or training to create a valuable application of the tool.
Until last week, programming languages (many of which were created by the open-source community) satisfied criteria #1 and #2, but not #3. Wielding these powerfully composable languages effectively required an untenable amount of technical knowledge for the average person.
With the introduction of ChatGPT and AlphaCode, the amount of technical knowledge required to create a valuable bespoke application has fallen dramatically. With a simple request, almost anyone can suddenly create a useful tool built from composable code using little more than a request in plain English.
Do what's good for humans, modeled on how humans already do things; ignore what's convenient for computers.
—Stewart Brand
There is no question that this moment represents an enormous leap in the trajectory of technology. With composability and usability reunited once more, the dream of early computation’s pioneers would be realized.
There’s just one glaring problem.
A Warning
Despite its name, OpenAI is not an open-source project. In fact, its largest investor is the very behemoth that once schemed to destroy open-source—Microsoft. In 2020, OpenAI announced that it would grant an exclusive license for GPT-3 to Microsoft, giving the company the sole power to embed, repurpose, and modify the model as it pleases.
To be clear, Microsoft under Satya Nadella is not Microsoft under Steve Ballmer. The company has in fact become a formidable contributor to the open-source community.
All the same, ChatGPT is anything but permissionless. We can’t look under the hood of the model or review the datasets that the model was trained on. Those that build tools or businesses on top of these APIs are taking a leap of faith. Access to this powerful tool is granted based on the terms determined by OpenAI and its investors.


To some concerned with the power of AI, this may be a good thing. As philosopher Nick Bostrom commented, "If you have a button that could do bad things to the world, you don't want to give it to everyone." But while OpenAI’s CEO Sam Altman has expressed good intentions, it’s unclear why a private organization with little oversight should be trusted with such a button either.
While OpenAI did open-source their multi-lingual transcription model, few expect GPT to receive the same treatment.
Instead, we’re enjoying permissioned user-friendly composability for the (likely brief) period of time while it is freely available. Time will tell what sort of limitations and fees may be placed on tools like ChatGPT or AlphaCode. In the meantime, the open-source community isn’t far behind.
What I'm wary of is that optimistic technologists are over extrapolating again: I see chatgpt (& similar) as this open-ended canvas that I can make things with. Other people can use this open-ended canvas to make things! Other people _will_ use this to make things!
Yes, there may be something different this time because the UI is just raw text. But so is a google search box.
Tim Wu's "The Master Switch" talks about how this isn't even limited to code. Same pattern of "open democratic exuberance leading to consolidation and oligopoly" happened for printing press, telegram, radio, television, the internet.